ADF High-Level File Structure
This section describes the high-level structure of the Allotrope Data Format (ADF).
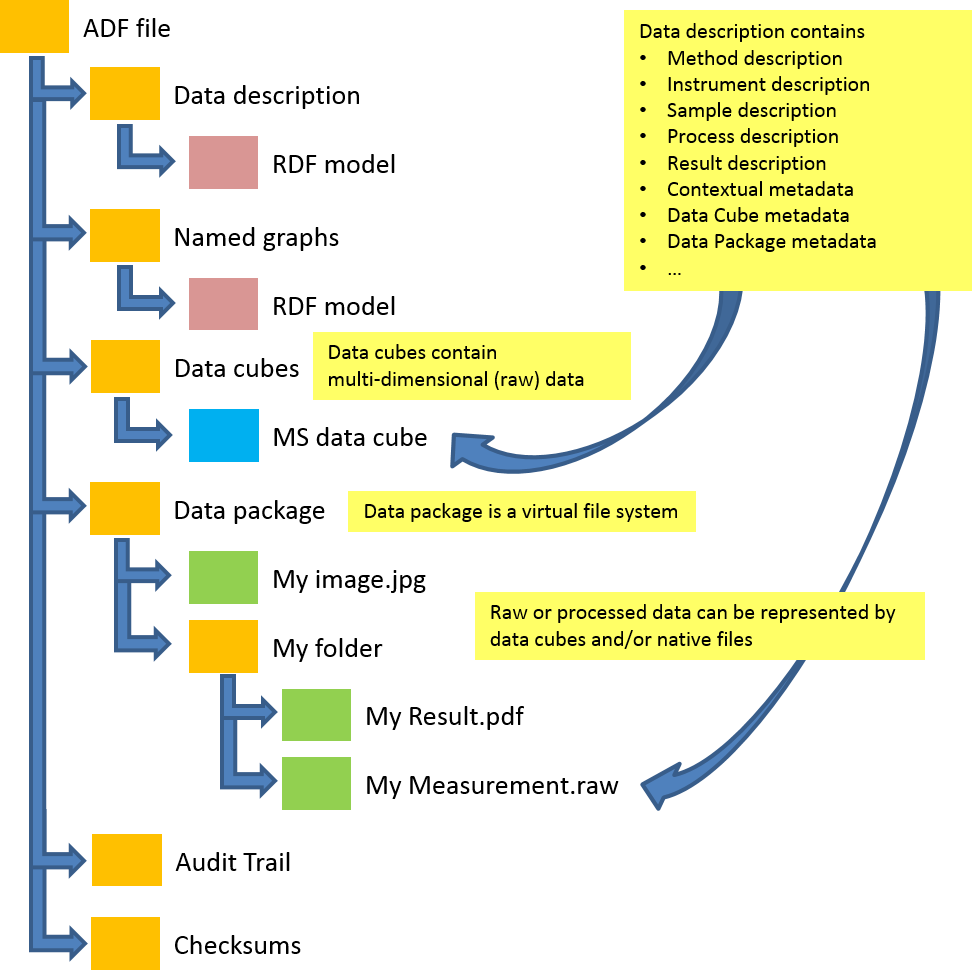
The following figure illustrates the high-level structure of ADF:
The Allotrope Data Format (ADF) is a family of specifications designed to standardize the acquisition, exchange, storage and access of analytical data captured in laboratory workflows. This document is an overview of ADF. It provides an entry point to its specifications and documentation:
THESE MATERIALS ARE PROVIDED "AS IS" AND ALLOTROPE EXPRESSLY DISCLAIMS ALL WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, INCLUDING, WITHOUT LIMITATION, THE WARRANTIES OF NON-INFRINGEMENT, TITLE, MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE.
The Allotrope Data Format (ADF) defines an interface for storing scientific observations from analytical chemistry. It is intended for long-term stability of archived analytical data and fast real-time access to it. This document provides an overview of the main components and links to corresponding specifications.
The document is structured as follows: Within the remaining part of the introduction, document conventions are described. In particular, naming conventions and a list of namespaces and corresponding prefixes are given that are used throughout different ADF specifications. Then, the general requirements for the ADF API stack and the different components are described. Detailed descriptions are available at the corresponding specifications.
The IRI of an entity has two parts: the namespace and the local identifier.
Within one RDF document the namespace might be associated by a shorter prefix.
For instance the namespace IRI http://www.w3.org/2002/07/owl# is commonly associated with the prefix owl:
and one can write owl:Class instead of the full IRI http://www.w3.org/2002/07/owl#Class.
Within the biomedical domain the local identifier is often an alphanumeric ID which is not human readable.
The Allotrope Foundation Ontologies [[!AFO]] follow this approach, e.g., a process is represented as af-p:AFP_0001617.
To enhance readability within this document, the preferred label from the ontology or taxonomy is used for the corresponding entity.
I.e., instead of af-p:AFP_0001617 the corresponding entity is named as
af-p:process.
If the namespace is clear by the context the prefix MAY be omitted and the entity is named simply process.
If the label contains spaces, the entity MAY be surrounded by guillemets to avoid ambiguities, e.g. «af-p:experimental method».
Within the ADF specifications, the following namespace prefix bindings are used:
| Prefix | Namespace |
|---|---|
| owl: | http://www.w3.org/2002/07/owl# |
| rdf: | http://www.w3.org/1999/02/22-rdf-syntax-ns# |
| rdfs: | http://www.w3.org/2000/01/rdf-schema# |
| xsd: | http://www.w3.org/2001/XMLSchema# |
| skos: | http://www.w3.org/2004/02/skos/core# |
| dct: | http://purl.org/dc/terms/ |
| sh: | http://www.w3.org/ns/shacl# |
| void: | http://rdfs.org/ns/void# |
| foaf: | http://xmlns.com/foaf/0.1/ |
| obo: | http://purl.obolibrary.org/obo/ |
| qudt: | http://qudt.org/schema/qudt# |
| unit: | http://qudt.org/vocab/unit# |
| qudt-quantity: | http://qudt.org/vocab/quantity# |
| qb: | http://purl.org/linked-data/cube# |
| ldp: | http://www.w3.org/ns/ldp# |
| adf-dp: | http://purl.allotrope.org/ontologies/datapackage# |
| adf-dc: | http://purl.allotrope.org/ontologies/datacube# |
| adf-dc-hdf: | http://purl.allotrope.org/ontologies/datacube-to-hdf5-map# |
| ex: | http://example.com/ns# |
Allotrope SHOULD use the common prefixes registered at prefix.cc.
Within this document the definitions of MUST, SHOULD and MAY are used as defined in [[!rfc2119]].
Within this document, decimal numbers will use a dot "." as the decimal mark.
This section describes the key requirements to the Allotrope Data Format (ADF).
The key requirements for ADF are:
This section describes the high-level structure of the Allotrope Data Format (ADF).
The following figure illustrates the high-level structure of ADF:
The following figure illustrates the high-level structure of the Allotrope Data Format (ADF) API stack.
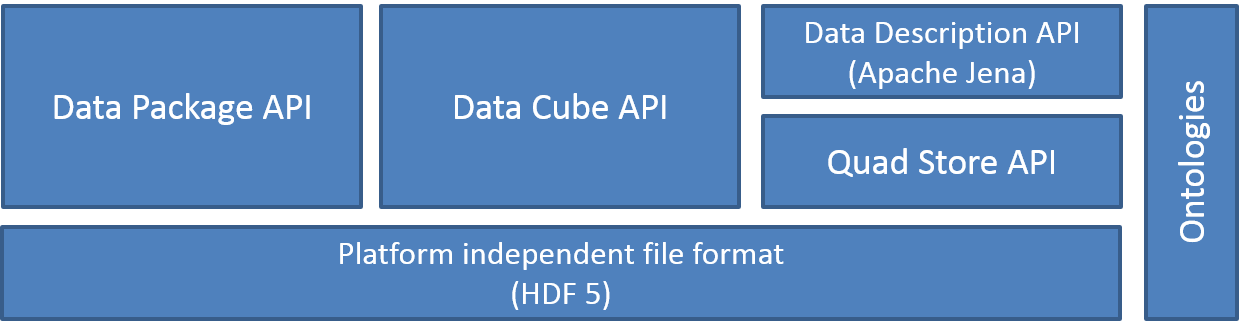
The Data Package API specification [[!ADF-DP]] defines how to store multiple (proprietary, binary, text) data files in a single package. The purpose of packaging is to ensure consistency and integrity of data files and metadata during storage and transfer. Files stored in the data package can represent source measurements or results of an experiment or process described in the data description. The vocabulary used within the ADF Data Package operations is described in the ADF Data Package Ontology [[ADF-DPO]].
The Data Cube API specification [[!ADF-DC]] defines how to store one- or multi-dimensional data. This can be source or processed data, which may be sparse. Data cubes represent measurements or results of an experiment or process described in the data description. The vocabulary used within the ADF Data Cube operations is described in the ADF Data Cube Ontology [[ADF-DCO]].
The Data Description API specification [[!ADF-DD]] defines how to store experiment or process descriptions and contextual metadata as well as metadata of Data Package and Data Cubes.
The Quadruple Store API specification [[!ADF-QS]] provides an efficient persistence layer for the RDF Data Model based on HDF5 [[!HDF5]]. It allows to store, query and retrieve RDF statements of the RDF Data Model.
The following figure shows the different ontologies that are used to describe data stored in ADF:
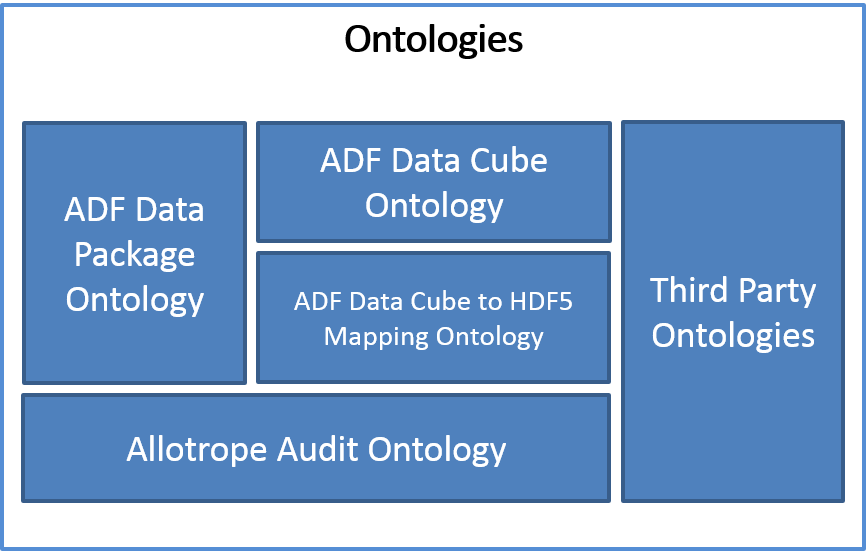
The ADF Data Package Ontology [[!ADF-DPO]] provides the vocabulary for the operations of the ADF Data Package API [[!ADF-DP]] on files and folders.
The ADF Data Cube Ontology [[!ADF-DCO]] provides the vocabulary for the descriptions of multi-dimensional data and the operations on them. It is used by the ADF Data Cube API [[!ADF-DC]].
The ADF Data Cube to HDF5 Mapping Ontology [[!ADF-DCO-HDF]] provides the vocabulary for the descriptions of the mapping between the functional representation of data cubes to their physical representation in HDF5 datasets.
The ADF Audit Ontology [[!ADF-AUDIT]] provides the vocabulary for the description of audit trail entries and electronic signatures.
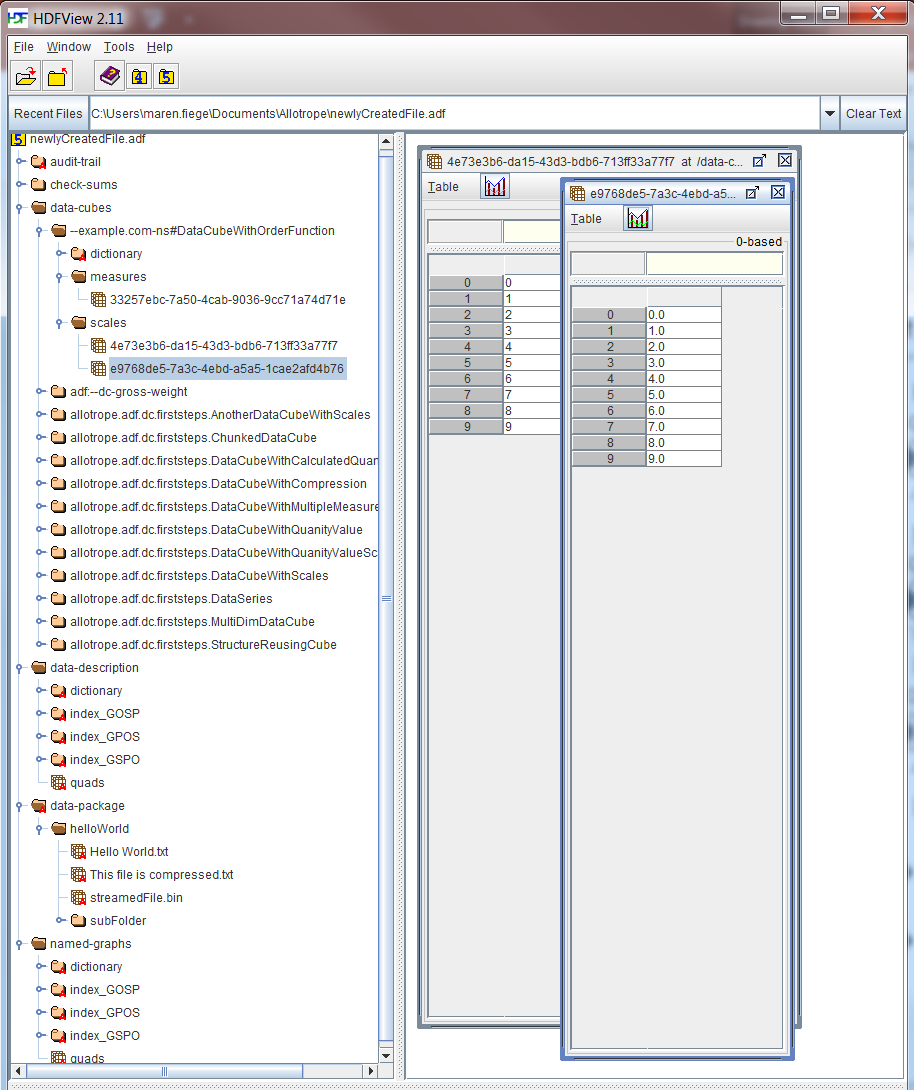
ADF uses HDF5 [[!HDF5]] as the underlying file format.
The following figure illustrates the basic layout of an ADF file in HDFView with the six components for data description, named graphs, data cube, data package, checksums and audit trail:
| Version | Release Date | Remarks |
|---|---|---|
| 0.3.0 | 2015-04-30 |
|
| 0.4.0 | 2015-06-18 |
|
| 1.0.0 RC | 2015-09-17 |
|
| 1.0.0 | 2015-09-29 |
|
| 1.1.0 RC | 2016-03-11 |
|
| 1.1.0 RF | 2016-03-31 |
|
| 1.1.5 | 2016-05-13 |
|
| 1.2.0 Preview | 2016-09-23 |
|
| 1.2.0 RC | 2016-12-07 |
|
| 1.3.0 Preview | 2017-03-31 |
|
| 1.3.0 RF | 2017-06-30 |
|
| 1.4.5 RF | 2018-12-17 |
|
| 1.5.0 RC | 2019-12-12 |
|
| 1.5.0 RF | 2020-03-24 |
|
| 1.5.3 RF | 2020-11-30 |
|